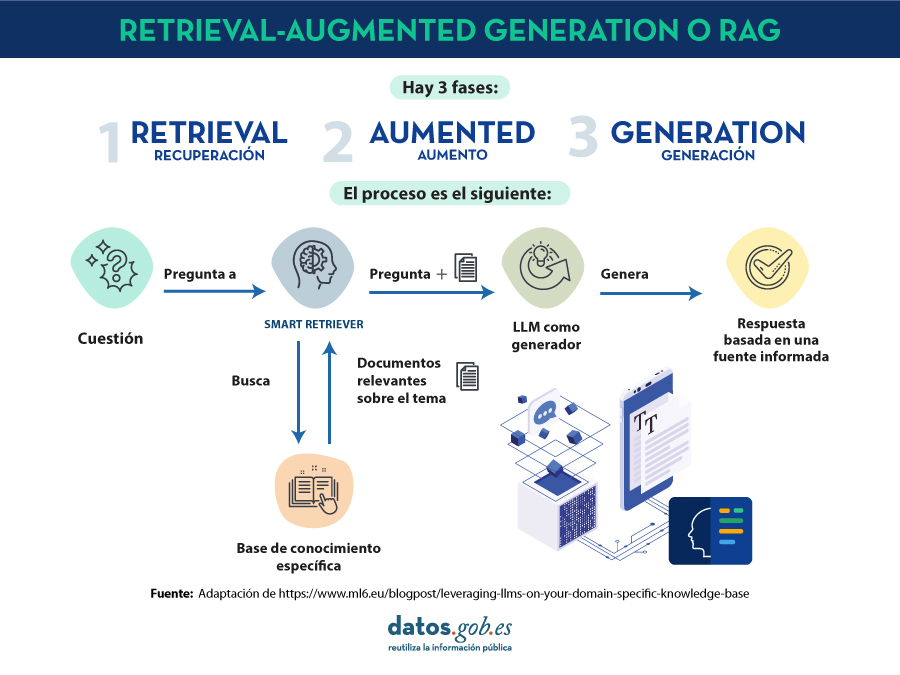
Introducció
En 2020, Patrick Lewis, un jove doctor en el camp dels models del llenguatge que treballava en l'antiga Facebook AI Research (ara Fique AI Research) publica al costat d'Ethan Perez de la Universitat de Nova York un article titulat: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks en el qual explicaven una tècnica per a fer més precisos i concrets els models del llenguatge actuals. L'article és complex per al públic en general. No obstant açò, en el seu blog , varis dels autors de l'article expliquen de manera més assequible com funciona la tècnica de el
en el qual explicaven una tècnica per a fer més precisos i concrets els models del llenguatge actuals. L'article és complex per al públic en general. No obstant açò, en el seu blog , varis dels autors de l'article expliquen de manera més assequible com funciona la tècnica de el
Els models grans del llenguatge o Large Language Models són models d'intel·ligència artificial que s'entrenen utilitzant algoritmes de Deep Learning sobre conjunts enormes d'informació generada per humans. D'esta manera, una vegada entrenats, han après la forma en la qual els humans utilitzem la paraula parlada i escrita, així que són capaces d'oferir-nos respostes generals i amb un patró molt humà a les preguntes que els fem. No obstant açò, si busquem respostes precises en un context determinat, els
. La prevalença de l'al·lucinació en els LLMs, estimada en un 15% o 20% para